Main Page: Difference between revisions
Jump to navigation
Jump to search
No edit summary |
|||
| (52 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
=== What is memcp? === |
=== What is memcp? === |
||
| + | [[File:Webapps.svg|left|frameless]] |
||
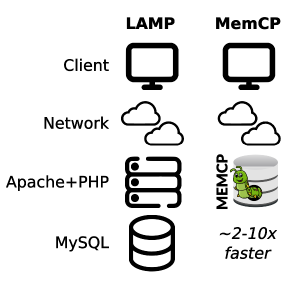
memcp is an open-source, high-performance, columnar in-memory database that can handle both OLAP and OLTP workloads. It provides an alternative to proprietary analytical databases and aims to bring the benefits of columnar storage to the open-source world. |
memcp is an open-source, high-performance, columnar in-memory database that can handle both OLAP and OLTP workloads. It provides an alternative to proprietary analytical databases and aims to bring the benefits of columnar storage to the open-source world. |
||
memcp is written in Golang and is designed to be portable and extensible, allowing developers to embed the database into their applications with ease. It is also designed with a focus on scalability and performance, making it a suitable choice for distributed applications. |
memcp is written in Golang and is designed to be portable and extensible, allowing developers to embed the database into their applications with ease. It is also designed with a focus on scalability and performance, making it a suitable choice for distributed applications. |
||
| ⚫ | |||
| ⚫ | |||
| − | * '''fast:''' MemCP is built with parallelization in mind. The parallelization pattern is made for minimal overhead. |
||
| + | |||
| ⚫ | |||
| − | * |
+ | *'''fast:''' MemCP is built with parallelization in mind. The parallelization pattern is made for minimal overhead. |
| ⚫ | |||
| + | *'''modern:''' MemCP is built for modern hardware with caches, NUMA memory, multicore CPUs, NVMe SSDs |
||
* '''versatile:''' Use it in big mainframes to gain analytical performance, use it in embedded systems to conserve flash lifetime |
* '''versatile:''' Use it in big mainframes to gain analytical performance, use it in embedded systems to conserve flash lifetime |
||
* Columnar storage: Stores data column-wise instead of row-wise, which allows for better compression, faster query execution, and more efficient use of memory. |
* Columnar storage: Stores data column-wise instead of row-wise, which allows for better compression, faster query execution, and more efficient use of memory. |
||
* In-memory database: Stores all data in memory, which allows for extremely fast query execution. |
* In-memory database: Stores all data in memory, which allows for extremely fast query execution. |
||
| − | * |
+ | *Build fast REST APIs directly in the database (they are faster because there is no network connection / SQL layer in between) |
| − | * |
+ | *OLAP and OLTP support: Can handle both online analytical processing (OLAP) and online transaction processing (OLTP) workloads. |
| − | * |
+ | *Compression: Lots of compression formats are supported like bit-packing and dictionary encoding |
* Scalability: Designed to scale on a single node with huge NUMA memory |
* Scalability: Designed to scale on a single node with huge NUMA memory |
||
| − | * |
+ | *Adjustable persistency: Decide whether you want to persist a table or not or to just keep snapshots of a period of time |
| + | [[File:MemCP Port.png|frameless]] |
||
| + | |||
| + | <youtube>g29FR4Jwius</youtube> |
||
| + | |||
| + | https://www.youtube.com/watch?v=g29FR4Jwius |
||
| + | |||
| ⚫ | |||
| + | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| + | *[[Persistency and Performance Guarantees]] |
||
| + | *[[Current Status and Open Issues]] |
||
| + | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| + | *[[Contributing]] |
||
| ⚫ | |||
| + | |||
| + | ====Administration==== |
||
| + | |||
| + | * [[Deployment]] |
||
| + | * [[Migration from MySQL and PostgreSQL]] |
||
| + | * [[Settings]] |
||
| + | *[[Process Hibernation]] |
||
| + | *[[Performance Measurement]] |
||
| + | *[[MemCP Console]] |
||
| + | |||
| + | ====Frontends==== |
||
| + | |||
| ⚫ | |||
| + | *[[Supported SQL]] |
||
| + | *[[Advanced SQL Tutorial]] |
||
| ⚫ | |||
| ⚫ | |||
| + | *[[How SQL Operators are implemented on MemCP]] |
||
| + | |||
| ⚫ | |||
| + | *[[Introduction to RDF]] |
||
| + | *[[Advanced Graph Querying]] |
||
| ⚫ | |||
| + | |||
| + | =====Custom Frontends===== |
||
| + | |||
| + | *[[In-Database WebApps|In-Database WebApps and REST Services]] |
||
| + | *[[Websockets in MemCP]] |
||
| + | |||
| ⚫ | |||
| + | |||
| + | =====How things work in MemCP===== |
||
| + | *[[Databases, Tables and Columns]] |
||
| ⚫ | |||
| + | *[[Shards, RecordIDs, Main Storage, Delta Storage]] |
||
| + | *[[Columnar Storage]] |
||
| + | *[[Transactions]] |
||
| + | =====Optimizations===== |
||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| + | *[[Temporary Columns]] |
||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| − | ** [[Replace MySQL with MemCP]] |
||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| ⚫ | |||
| Line 45: | Line 89: | ||
| − | === |
+ | ===Further Reading=== |
[https://github.org/launix-de/memcp MemCP on Github] |
[https://github.org/launix-de/memcp MemCP on Github] |
||
| − | ==== |
+ | ====Scientific==== |
| − | * |
+ | *[https://www.vldb.org/pvldb/vol13/p2649-boncz.pdf VLDB Research Paper] |
| − | * |
+ | *[https://cs.emis.de/LNI/Proceedings/Proceedings241/383.pdf LNI Proceedings Paper] |
| − | * |
+ | *[https://wwwdb.inf.tu-dresden.de/wp-content/uploads/T_2014_Master_Patrick_Damme.pdf TU Dresden Research Paper] |
| − | * |
+ | *[https://www.dcs.bbk.ac.uk/~dell/teaching/cc/paper/sigmod10/p135-malewicz.pdf Large Graph Algorithms] |
| − | * |
+ | *https://wwwdb.inf.tu-dresden.de/research-projects/eris/ |
| − | ==== |
+ | ====How MemCP was built==== |
| − | * |
+ | *[https://launix.de/launix/how-to-balance-a-database-between-olap-and-oltp-workflows/ Balancing OLAP and OLTP Workflows] |
| − | * |
+ | *[https://launix.de/launix/designing-a-programming-language-for-distributed-systems-and-highly-parallel-algorithms/ Designing Programming Languages for Distributed Systems] |
| − | * |
+ | *[https://launix.de/launix/on-designing-an-interface-for-columnar-in-memory-storage-in-golang/ Columnar Storage Interface in Golang] |
| − | * |
+ | *[https://launix.de/launix/how-in-memory-compression-affects-performance/ Impact of In-Memory Compression on Performance] |
| − | * |
+ | *[https://launix.de/launix/memory-efficient-indices-for-in-memory-storages/ Memory-Efficient Indices for In-Memory Storages] |
| − | * |
+ | *[https://launix.de/launix/on-compressing-null-values-in-bit-compressed-integer-storages/ Compressing Null Values in Bit-Compressed Integer Storages] |
| − | * |
+ | *[https://launix.de/launix/when-the-benchmark-is-too-slow-golang-http-server-performance/ Improving Golang HTTP Server Performance] |
| − | * |
+ | *[https://launix.de/launix/how-to-benchmark-a-sql-database/ Benchmarking SQL Databases] |
| − | * |
+ | *[https://launix.de/launix/writing-a-sql-parser-in-scheme/ Writing a SQL Parser in Scheme] |
| − | * |
+ | *[https://launix.de/launix/accessing-memcp-via-scheme/ Accessing memcp via Scheme] |
| − | * |
+ | *[https://launix.de/launix/memcp-first-sql-query-is-correctly-executed/ First SQL Query in memcp] |
| − | * |
+ | *[https://launix.de/launix/sequence-compression-in-in-memory-database-yields-99-memory-savings-and-a-total-of-13/ Sequence Compression in In-Memory Database] |
| − | * |
+ | *[https://launix.de/launix/storing-a-bit-smaller-than-in-one-bit/ Storing Data Smaller Than One Bit] |
| − | * |
+ | *[https://www.youtube.com/watch?v=DWg4nx4KVLo memcp Announcement Video] |
Latest revision as of 20:14, 20 November 2024
What is memcp?

memcp is an open-source, high-performance, columnar in-memory database that can handle both OLAP and OLTP workloads. It provides an alternative to proprietary analytical databases and aims to bring the benefits of columnar storage to the open-source world.
memcp is written in Golang and is designed to be portable and extensible, allowing developers to embed the database into their applications with ease. It is also designed with a focus on scalability and performance, making it a suitable choice for distributed applications.
Features
- fast: MemCP is built with parallelization in mind. The parallelization pattern is made for minimal overhead.
- efficient: The average compression ratio is 1:5 (80% memory saving) compared to MySQL/MariaDB
- modern: MemCP is built for modern hardware with caches, NUMA memory, multicore CPUs, NVMe SSDs
- versatile: Use it in big mainframes to gain analytical performance, use it in embedded systems to conserve flash lifetime
- Columnar storage: Stores data column-wise instead of row-wise, which allows for better compression, faster query execution, and more efficient use of memory.
- In-memory database: Stores all data in memory, which allows for extremely fast query execution.
- Build fast REST APIs directly in the database (they are faster because there is no network connection / SQL layer in between)
- OLAP and OLTP support: Can handle both online analytical processing (OLAP) and online transaction processing (OLTP) workloads.
- Compression: Lots of compression formats are supported like bit-packing and dictionary encoding
- Scalability: Designed to scale on a single node with huge NUMA memory
- Adjustable persistency: Decide whether you want to persist a table or not or to just keep snapshots of a period of time

https://www.youtube.com/watch?v=g29FR4Jwius
Introduction
- What is OLTP and OLAP
- History of the MemCP project
- Hardware Requirements
- Persistency and Performance Guarantees
- Current Status and Open Issues
Getting Started
Administration
- Deployment
- Migration from MySQL and PostgreSQL
- Settings
- Process Hibernation
- Performance Measurement
- MemCP Console
Frontends
SQL Frontend
- Supported SQL
- Advanced SQL Tutorial
- SQL over REST
- Supported Tooling
- How SQL Operators are implemented on MemCP
RDF Frontend
Custom Frontends
Internals
How things work in MemCP
- Databases, Tables and Columns
- Shards, RecordIDs, Main Storage, Delta Storage
- Columnar Storage
- Transactions
Optimizations
- In-Memory Compression, Columnar Compression Techniques
- Temporary Columns
- Data Auto Sharding and Auto Indexing
- Parallel Computing

Further Reading
Scientific
- VLDB Research Paper
- LNI Proceedings Paper
- TU Dresden Research Paper
- Large Graph Algorithms
- https://wwwdb.inf.tu-dresden.de/research-projects/eris/
How MemCP was built
- Balancing OLAP and OLTP Workflows
- Designing Programming Languages for Distributed Systems
- Columnar Storage Interface in Golang
- Impact of In-Memory Compression on Performance
- Memory-Efficient Indices for In-Memory Storages
- Compressing Null Values in Bit-Compressed Integer Storages
- Improving Golang HTTP Server Performance
- Benchmarking SQL Databases
- Writing a SQL Parser in Scheme
- Accessing memcp via Scheme
- First SQL Query in memcp
- Sequence Compression in In-Memory Database
- Storing Data Smaller Than One Bit
- memcp Announcement Video